
This post is obsolete
This blog post is quite old, and a lot has changed since then. Meanwhile, I have changed employer, blogging platform, software stack, infrastructure, interests, and more.
You will probably find more recent and relevant information about the topics discussed here elsewhere.
Still, this content is provided here for historical reasons, but please don’t expect it to be current or authoritative at this point.
Thanks for stopping by!
I Am a Mobile Sensor Network, Collecting Big Data
Don’t worry, this is not a desperate attempt at SEO for my blog (although I do appreciate your likes, Tweets, RSS subscriptions and other ways you help me reach a wider audience), nor is this my entry into the latest contest of IT BS Bingo.
It just occurred to me yesterday that Big Data is everywhere. Even during your weekend jogging run.
Collecting Fitness Data, Step by Step, Heartbeat by Heartbeat, on Your Phone
For Christmas, I bought myself a Wahoo Fitness Key (no longer available) and its matching ANT+ heart rate monitor (HRM) (no longer available). The key plugs into your iPhone and provides connectivity to the ANT+ wireless sensor protocol. The HRM is another dongle that straps around your chest and electrically registers every heart beat, then transmits the data to the Wahoo key. If you have an iPhone 4S, you can do without the key and just buy a Bluetooth HRM like the Wahoo BlueHR (no link, page no longer exists), because iPhone 4 supports Bluetooth 4.0 which includes a low power version of the protocol that supports sensor collection devices such as HRMs that run off of a coin cell.
So iPhone + Wahoo + HRM = Wireless Sensor Network. And if your idea of a network involves more than two participants, Wahoo also sells an ANT+ pedometer (no longer available) to measure your stepping frequency along with heart beat data as well.
(Android users: I’m sure you’ll find a similar solution for yourselves as well. I just happen to prefer quality over popularity.)
Running 2.0
Thanks to modern gadgetry, apps like iSmoothRun (no link, ismoothrun.com no longer exists) on my phone can now tell me how I’m doing while I’m running, including time, distance (thanks to GPS, which is another sensor), pace, cadence (using the phone’s accelerometer or a wireless pedometer and heart rate. I can also set up a target running profile (like “No more than 70% of max. heart rate so I can stay in the aerobic zone, please.”) and my phone will duck the music and tell me to slow down whenever I go beyond target heart rate.
Pretty cool.
Social Network Running
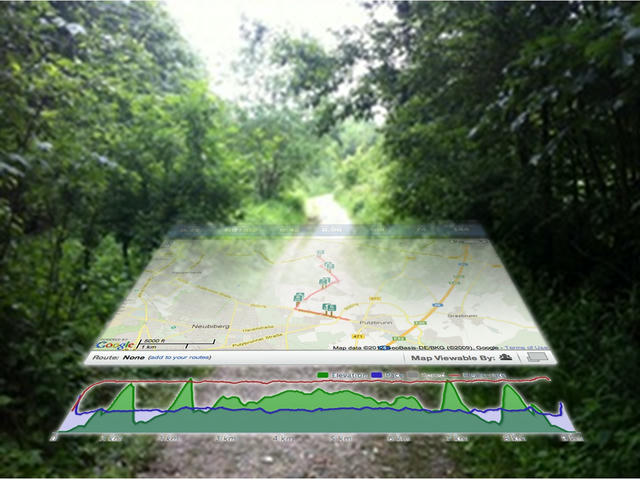
But we live in the age of web 2.0 so there’s obviously more to do if you want to maintain your running geek-cred: The iPhone also collects all data (position, heart-beats, and steps) over time and at the end of the run, it will not only present me with my running statistics, possibly spiced up with current weather data etc., it will also offer to upload the data to one of the emerging fitness social networks, such as RunKeeper.com (no link, page no longer exists).
Sites like Runkeeper take the data and create web maps with my running path, complete with nice graphs that I can dive into for analyzing my own running behavior including altitude, pace, heart rate, cadence etc. They also collect other data such as weight and body fat percentage (yes, using a Withings Scale) for example, you can track weight/bodyfat data too, even data from a sleep tracking system can be collected!) and show you your running (or fat loss) progress over time.
And thanks to social network goodness, you can run with friends over the network and compare statistics even if you’re not physically running at the same time. Or the same place.
And this is where Big Data comes into play, but what is it and how does it work?
The Advent of Big Data
The first time I heard about big data was during an internal workshop about the Sun Cloud in 2009 (you know, the old Sun habit of being way before our time). While we contemplated the implications of cloud computing for enterprises, someone mentioned that this would be nothing compared to the implications of Big Data. Back then, Big Data was reserved to web giants like Google and Yahoo! and the occasional large research institute such as CERN.
Big Data is the art of handling (surprise!) large amounts of data. “Large” can be anywhere starting at a dozen of Terabytes or a couple of Petabytes or any large number that no-one in their right mind would place into a single database on a single server.
Big Data has been made popular by innovations from web companies like Google, Yahoo, Facebook or Twitter, who pioneered new ways of handling huge amounts of data.
Today, Big Data is about to cross the chasm from the domain of a few innovators and early adopters to the early majority, as businesses start to realize its value.
The Four V’s of Big Data
Big Data is typically associated with four V’s:
Volume, meaning lots and lots of data from sensors, devices, social networks, the web, retail offices, mobile fleets, etc.,
Variety, meaning there’s no predefined structure in the data that one can rely on: Unstructured data. This is the main differentiator against classic data ware-housing, which is strictly structured.
Value, meaning that somewhere within that data, there is some valuable information to extract, though most of the pieces of data individually may seem valueless.
Velocity, meaning quick turnaround cycles, quick, almost real-time processing and also short innovation cycles. Fail fast, fail often is the mantra, until you hit data gold.
RunKeeper and Big Data
Let’s come back to our running example: RunKeeper is a Big Data company because it collects GPS, heart rate, cadence and other data from its millions of users. Assuming that only half of their 6 million users actually use the service for real, and that they run once a week and assuming a data size of 50 KByte per run (including GPS positions), we get 7.8 TByte of data per year. This is not a lot by Big Data standards, and it is quite structured, but when you combine this data with Tweets, Facebook status updates, other exercise data and nutrition/sleep data (RunKeeper does all of the above), then data volume easily increases to more than 10 TB per year, which is quite a lot to wade through.
And if you start counting records, the complexity is overwhelming: Each GPS sample is about 100 Bytes, which means that RunKeeper’s 10TB per year translates into roughly 100 Billion records to correlate, analyze and create meaning from.
What meaning?
The Meaning of Big Data
And that is the goal of Big Data: To create meaning out of billions of records that seem so innocent, if looked at individually. In the RunKeeper example, they create graphs of your running history and help you analyze and optimize your fitness either for free or as a paid, “pro” service. And thanks to their Health Graph API (no link, page no longer exists), an eco-system of other applications and companies emerges who slice and dice RunKeeper’s data in other creative ways, trying to create valuable (and monetizable) meaning out of it. Example: World-Rank.in (no link, world-rank.in no longer exists) collects data from RunKeeper and Twitter, then ranks runners into its own top 30 lists.
Other companies use Big Data to identify patterns in their customer’s behavior, find threats or opportunities to act upon, or simply alert hospitals that a new flu epidemic is about to hit them.
How Big Data Works
Most Big Data use cases work around the same pattern:
Aquire: Data is collected. Speed and scalability is critical here, not necessarily high availability. It’s ok to be offline for a few minutes, even hours, or to lose the occasional data record, but it’s important to catch as much as possible. The Hadoop framework and file system and/or NoSQL databases are key tools at this step.
Organize: To make large amounts of data manageable, a divide and conquer approach is taken: Data is mapped to some interesting nomenclature/metric/attribute (For example: is this a positive of a negative tweet? What company is this tweet about? Was that run a new record or a below-average result?), then the data is reduced into a more condense form (“Number of negative tweets that mention our company”, “Fastest 10k runs per country”, etc.). These two steps are the key in the MapReduce framework and can be used repeatedly and creatively to compose a new, more valuable data source, like: “Top 10 keywords associated with negative feelings towards your company.”, or “Top runners per age category and country”, or “Best training improvement over the last year”, or even crazy stuff like “Fastest music to run with”.
Analyze: With that kind of data and processing at your fingertips, new kinds of insight are possible that can be analyzed and acted upon. Which flights are delayed and carry unhappy social media celebrities so you better take good care of them? How about sponsoring your top runner in a certain category and create a celebrity out of her/him? Of course, valuable analysis can also be monetized. Perhaps some research institute or some sports company is interested in getting access to all that heart beat, speed and nutrition data (anonymized of course)?
Oracle and Big Data
Don’t worry, this commercial break will be brief, but interesting:
Oracle’s big strengths of course are in handling commercial data warehouses and analyzing business information data, as well as building Engineered Systems that remove the pain of setting up an IT shop while optimizing the usefulness you get from your systems.
Big Data’s strength lies in its innovation to handle and organize unstructured, large data sets, through the Hadoop filesystem, the MapReduce framework, the R statistical language and other emerging technologies. But analyzing data after these steps is still in it infancy.
By combining the worlds of Big Data, Data Warehousing and Business Intelligence, running on Engineered Systems, Oracle can offer unique value to businesses who want to leverage Big Data for their benefit, without going through the trial/error/research of running their own Big Data development operations.
Learn more from Oracle’s Big Data White Paper (no link, conv.me no longer exists), it’s really good, and check out Oracle’s Big Data home page (no link, conv.me no longer exists).
Building your own Sensor Driven Big Data Collection Network
As you can see, Big Data is fun and healthy. Here, we discussed some gadgets to get your own Sensor Network based Big Data collection infrastructure set up that feeds into RunKeeper and other Big Data collecting social networks for your analytical pleasure.
Big Data and You
What are your favorite Big Data examples? Do you see Big Data being used in your company? Have you played with collecting, organizing and analyzing Big Data yourself? Leave a comment and share!
Finally, here’s a video that shows the beauty of collecting, organizing, analyzing and visualizing of Big Data:

And if you want to see my own small chunks of running data, feel free to join my Street Team on RunKeeper (no link, page no longer exists).
Disclaimer: Neither me nor Oracle are affiliated with RunKeeper (Not that I know of). I just think it’s a cool service.
Update (2025-04-22): Removed affiliate links and associated widgets.